
When AI reaches industrial operations, accuracy stops being enough


Industrial companies do not lack data. They lack a layer where machines can consume that data with the same confidence that experienced engineers do. That gap stays invisible during dashboards and reports. It becomes a blocker the moment copilots, agents, or automated workflows start influencing real decisions – quoting, planning, maintenance, delivery.
AI in industry is shifting from insights to decisions. Not just chat interfaces. Copilots and agents now draft service reports, propose delivery dates, recommend maintenance actions, support quoting, and automate parts of planning and customer communication.
When AI explores, imperfect data is inconvenient. When AI influences operations, imperfect data is a risk. The issue is rarely wild inaccuracy. It is fragmentation and unstable meaning across ERP, PLM, MES, historians, maintenance, quality, and service systems that people can interpret but machines cannot.
Industrial fragmentation is normal
Industrial systems evolve over years. Operations expand, lines change, vendors differ, acquisitions happen, and temporary integrations become permanent. Segmented networks keep domains apart. Each system holds only part of reality. People reconcile the gaps on the fly. Machines do not.
“Each system holds only part of reality. People reconcile the gaps on the fly. Machines do not.”
What changes when machines consume data
Copilots, agents, and automated workflows consume structure. They apply patterns to whatever they see.
They implicitly assume that:
- identity is consistent across systems
- business logic is defined once, not reimplemented everywhere
- operational context is explicit, not implied
- contradictions are resolved with rules and precedence, not left for people to interpret
These conditions are only partly true in most industrial architectures. AI will still produce answers. The problem is not that the answers look obviously wrong. The problem is that they are fragile, hard to reason about, and unsafe to scale.
Why adding AI to each system increases risk
Attaching AI to individual systems sounds efficient. In practice it multiplies disagreement. ERP sees commitments and costs with delays. MES runs at another grain. Historians see signals with limited context. Maintenance tracks work orders and taxonomy. Quality tracks nonconformities and holds. If each domain hosts its own intelligence, outputs disagree quietly and expensively. Teams end up reconciling whose AI is right instead of improving the process.
This is not a model problem. It is an architectural problem.
“Teams end up reconciling whose AI is right instead of improving the process.”
The missing layer: a machine‑readable decision foundation
For machines to be useful in operations, they need one place where reality is:
- consolidated across systems
- structured with clear entities and relationships
- enriched with context such as units, calendars, and taxonomies
- governed and traceable with lineage and change control
- time‑aware so you can reproduce what was known at decision time
This is not a dashboard layer or a reporting warehouse. It is a decision foundation that acts as the interface between operational systems and anything that reasons over them. Analytics,
automation, and AI consume the same governed semantics. The foundation constrains what machines can see and do. That constraint is what makes outputs usable.
Integrated analytics environments – Microsoft Fabric is one example – make this practical by keeping semantics, pipelines, and governance close to each other. But the platform supports the method. The method stays the point.
“This is not a dashboard layer or a reporting warehouse. It is a decision foundation.”
What high‑quality data means for AI in industry
The decision foundation is the architecture. These are the properties that make it trustworthy.
High quality for AI is more than accuracy. It means five properties are explicit and testable:
- conformed identity for assets, products, work centres, customers, and sites
- versioned definitions for scrap, downtime, yield, lead time, and service completion
- time semantics that align events, postings, batches, and shift calendars
- grain contracts that control how order, operation, and sensor data combine
- lineage from decision back to sources and rules
Without this, copilots remain demos and agents remain experiments.
Why most existing data platforms still fall short
Many companies already operate a data warehouse or a data lake. Pilots still stall because data is not engineered into a reusable decision asset. Core entities are not conformed. Definitions live in dashboards and spreadsheets. Logic is rebuilt in every report and model. Lineage is not strong enough for operational use. When people must reinterpret meaning, machines cannot safely take over parts of the reasoning.
A pragmatic way to build it: Building Blocks
Skip multi‑year platforms. Skip isolated pilots. Build the foundation in Building Blocks. Each block delivers a real operational outcome and leaves behind reusable assets for the next block.
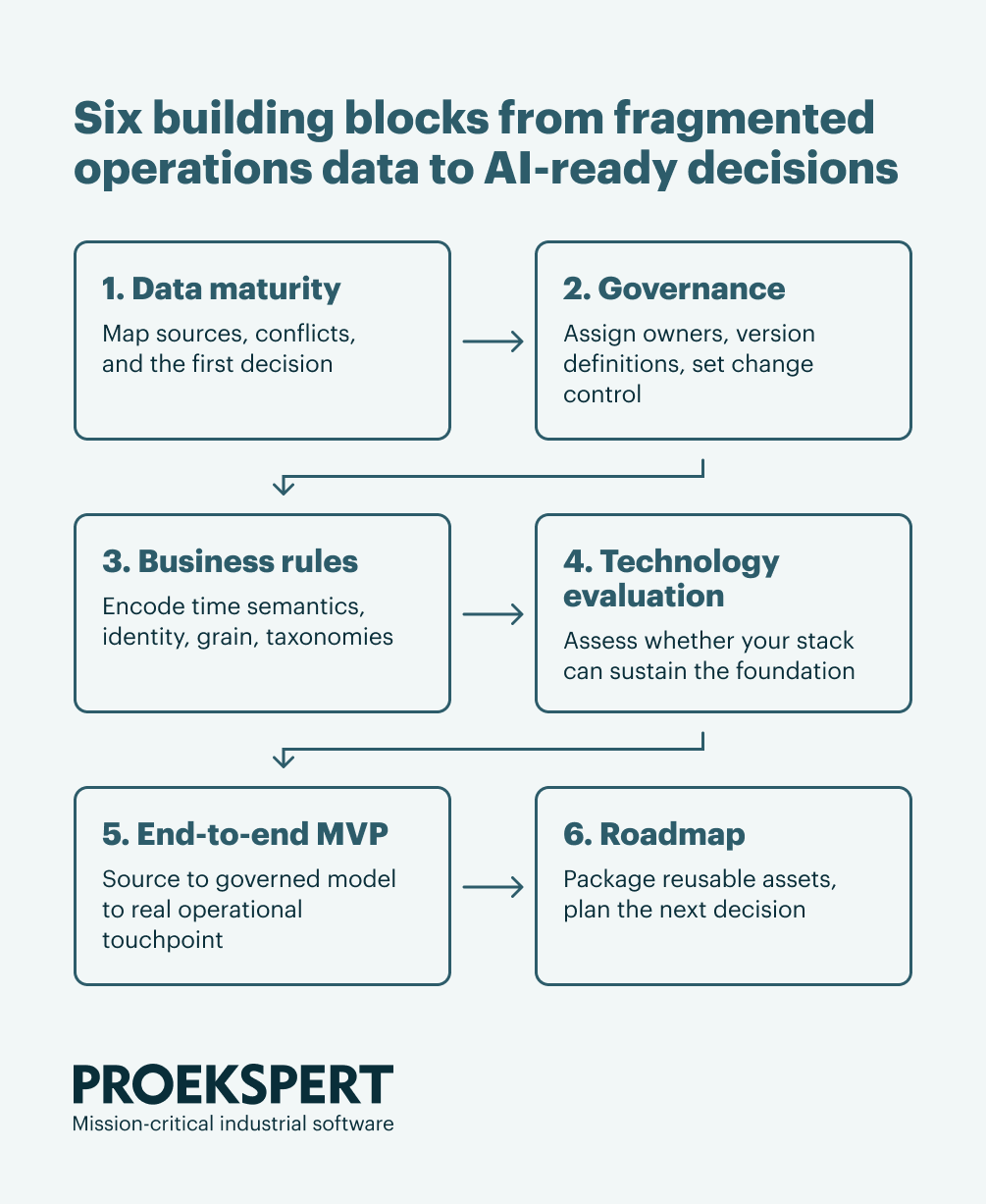
1. Data maturity, fast and practical
Pick one decision where scale matters. Map sources, constraints, and semantic conflicts. Define success and risk in operational terms.
Outputs
- Decision statement and guardrails
- Source map across ERP, PLM, MES, historians, maintenance, and quality, including time bases and latency
- List of definition conflicts that block safe automation
2. Lightweight governance on what matters
Assign owners for the few things that make-or-break safe decisions.
Outputs
- Owners for asset, product, work center, customer, site
- Versioned definitions for scrap, downtime, yield, lead time, installed base, service completion
- Change control and lineage expectations for decision‑critical logic
3. Business rules that make meaning explicit
Turn industrial reality into machine‑usable rules.
Outputs
- Time semantics, shift calendars, unit conversions, exception handling, and taxonomies encoded as tests
- Identity resolution across ERP and MES for assets, orders, and variants
- Grain bridging contracts that explain how to combine order, operation, and sensor levels
- Rule tests with golden datasets and lineage back to sources
4. Technology evaluation
Have an unbiased look at whether your current stack can sustain the decision foundation at the required scale and pace. If it can, use it. If not, identify a more optimal stack that delivers the semantics, lineage, security boundaries, and developer ergonomics you need, without losing sight of the bigger picture.
What we evaluate
- Ability to model and serve a shared semantic layer to analytics and AI
- Native support for time semantics, rule versioning, data quality testing, and lineage
- Integration paths to ERP, PLM, MES, historians, maintenance, and quality
- Security and access patterns that respect OT boundaries while enabling governed consumption
- Cost and sustainability over multiple blocks, not just the first build
- Fit with team skills and operating model
- Migration risk and how to reuse what already works
Typical outcomes
- Keep and harden the current approach with clear guardrails
- Evolve to an integrated environment that combines ingestion and orchestration, lakehouse and warehouse patterns, a shared semantic model, and built‑in governance
- A transitional plan that reuses existing pipelines and content where possible
This is where a platform like Fabric earns its place – not as a strategy, but as infrastructure that makes each building block reusable for the next one.
5. End‑to‑end MVP in a real workflow
Run from source to governed model to a real touchpoint. Include data quality checks, lineage, and a semantic layer so results do not change silently. Keep a human in the loop where risk is high.
Outputs
- Pipelines with tests and lineage from source to decision
- Semantic model that analytics and agents can query
- Operator or planner UI and a documented human‑in‑the‑loop boundary
- Runbook, SLA, and rollback criteria
6. Next steps and roadmap
Capture what is reusable and expand to the next adjacent decision.
Outputs
- Conformed entities, connectors, definitions, and rule tests packaged for reuse
- Short list of adjacent decisions now cheaper because semantics exist
- Change log tying source changes to rule versions
- Visibility and understanding of what is going to happen and when
How this works in practice: quoting in complex manufacturing
A European manufacturer of complex, engineer-to-order products wanted to improve how quoting decisions were supported. The challenge was not lack of data. It was fragmentation. Operational signals, cost drivers, and historical production performance lived across multiple systems. Experienced people bridged those gaps effectively, but the process was difficult to scale or transfer.
We did not add intelligence to individual systems. We built the decision foundation on the existing landscape and implemented it in an integrated environment. Operational and business data moved into one governed layer with a semantic model that both analytics and AI could use.
The results were concrete:
- Process behaviour that was previously hard to share across teams became visible and queryable
- Sales gained a shared, governed view of how production choices affect price and delivery
- The knowledge of the most experienced people became embedded in the system, available to the whole team rather than locked to a few individuals
- The foundation built for quoting is now reusable for adjacent decisions – planning, delivery performance, cost analysis
This is the pattern we repeat across use cases. The decision changes – quoting, planning, maintenance, delivery performance – but the method stays the same. One foundation, built in blocks, reusable for the next problem.
Where industrial AI actually fails
Industrial AI rarely fails at the model layer. It fails when machines are allowed to combine signals across domains, reason over operational state, and act without human reinterpretation. At that point, the absence of a machine‑readable decision layer becomes visible. This is why many AI initiatives stall after pilots. Not because the technology stops working, but because the risk becomes impossible to justify.
What experienced teams do differently
They invest first in a decision foundation that integrates fragmented systems, encodes business and operational logic once, serves humans and machines equally, and stays stable as tools and models change. With that in place, AI becomes practical and safe in operations.
The difference between experimenting and being ready
You do not need AI everywhere. You need one place where machines can reliably interact with operational reality. That place is not a model, a prompt, or a copilot. It is a decision foundation designed for machine consumption and delivered in repeatable Building Blocks. The platform helps, but the method is what reduces delivery risk.
Start with a data maturity assessment
The first building block – a lightweight data maturity assessment – takes days, not months. It maps your current landscape, identifies the highest-value decision to target first, and gives you a concrete starting point. We run these as standalone engagements with no commitment to continue.
To discuss how this applies to your situation, contact Urmas Kobin – or see how we engineer AI-ready data platforms end-to-end.
About Proekspert
Proekspert is a European industrial software engineering partner with over 30 years of experience building mission-critical systems for manufacturers and OEMs. We modernize legacy systems, develop secure connected products, and deliver cybersecurity compliance — including IEC 62443 and the EU Cyber Resilience Act. Our expertise spans embedded software, device-to-cloud integration, industrial AI, and cybersecurity for regulated sectors.







