
Building machines that read and write
A talk by Sean Gourley, CEO at San Francisco-based startup, Primer AI, at North Star AI conference, powered by Proekspert.
Many groundbreaking ideas were presented at North Star AI conference this year. Among them was a technological development that touches on what has been a strictly human endeavor in the past. Sean Gourley, CEO and Founder of Primer AI, showed us how his company is building machine intelligence that can read and write.

Gourley began his presentation by talking about complexity. “We live in a complex world that is difficult for us to understand as humans,” he said. As the challenges we face grow larger and more difficult, we won’t be able to make decisions about the future using the human brain alone—the complexity of the world is too great. By using AI, he argued, we can amplify the way we think and change the complexity of what we understand, ultimately accelerating our ever-increasing knowledge of the world.
“We are automating the generation of intelligence to give humans a leg up in understanding the complexity of the world we live in,” said Gourley.
Reading and writing are essential to understanding. These capacities allow us to observe the world, find insights, and communicate those findings. In Primer’s model, machines will be doing the initial observing and insight-finding, and humans will take on cognition and analysis from there. Concretely, this process means machines monitoring everything that has ever been written and published online.
How Primer Works in Artificial Intelligence and Machines Monitoring
What drives Primer is a set of core analytic engines. These engines allow Primer to configure various techniques that automate the functions of human analysts.
First there is the Structure Engine, which finds the innate structure in a general text. It breaks data down at the sentence level and creates a sort of fingerprint of a document. Second is the Event Engine, which identifies events such as global news or a rumor like “Apple is building a self-driving car.”
Third is the Ensemble Engine, which takes into consideration the fact that information never exists by itself but is often repeated. This engine will find the best, most-reliable, representation of some piece of information or estimate the mean point of numeric data. It can even find consensus as well as contradictions about a certain topic. Fourth is the Context Engine, which places an event within a timeline, showing how it evolved over time. The Context Engine also has the power to analyze and find supporting evidence for claims, facts, and assertions.
Fifth is the Difference Engine, which allows you to take any two corpuses of information and compare them. This can be types of news, social versus mainstream media, or two different languages. Here, Gourley noted that only fifty percent of information moves from one language to another. Primer allows you to easily access information that is otherwise locked away due to language barriers. After these five stages, there finally comes the sixth Story Engine, which is essentially a machine-generated intelligence briefing. This engine can also generate profiles on people and specific topics, much like Wikipedia articles.
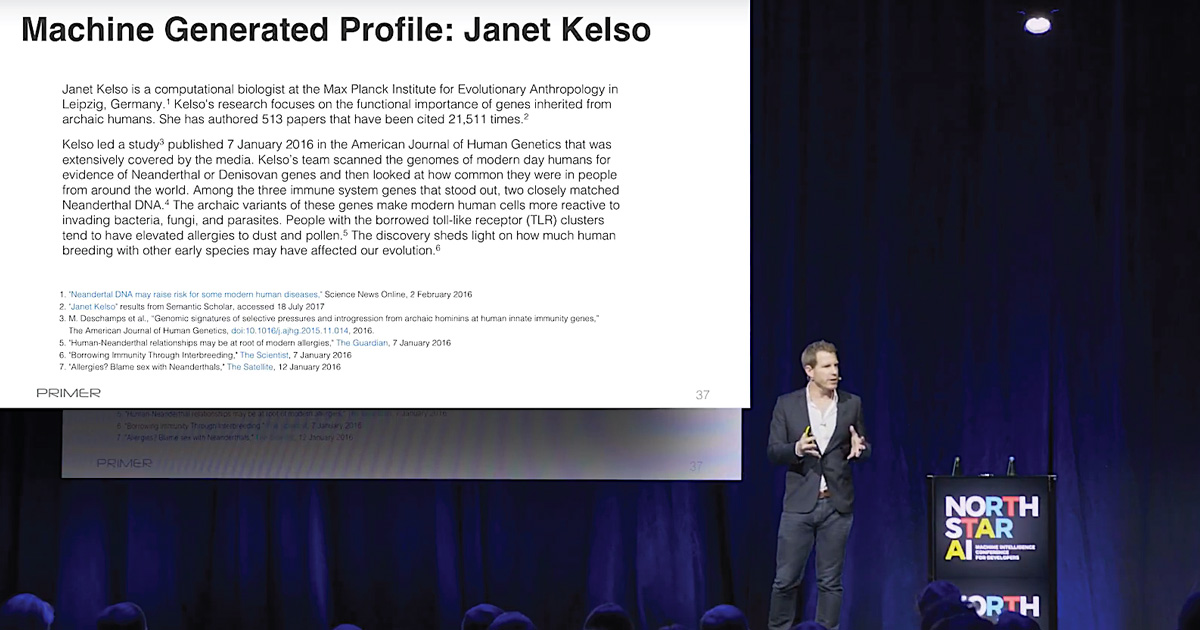
These six Primer engines work together to generate analysis from vast quantities of information. Using Primer to get automated-insights is simple, said Gourley. In some cases, it’s as simple as typing in a query and receiving a comprehensive briefing on any subject. This information can even be augmented by infographics and other visual data representations also generated by Primer’s engines.
One of the use-cases presented by Gourley was the tracking of how various media establishments report on a given event. For example, he noted that Primer can aggregate information (both visual and verbal) that demonstrates how Russian and American media covered the same terrorist attack, providing valuable insight into discrepancies and similarities between the two. This sort of analysis is just the tip of the iceberg when it comes to deriving meaningful information through Primer’s multi-engine process.
Primer is a young startup, but its customers already include GIC (a sovereign wealth fund based in Singapore), Walmart, and IQT (the corporate arm of the US intelligence agencies). These three are very different kinds of corporations but they all share one thing—they have too much data and not enough people to process it. This kind of challenge obviously demands automation.

Concerning Fake News
During his talk Gourley pointed out that if machines are parsing through information available on the internet, they must be aware of content that might be classified as fake news or bots deployed to influence political discourse.
According to Gourley, fake news succeeds today because the political media landscape is very complex and people have a hard time understanding it. For this reason, they are easily manipulated by very primitive technology. “It’s an asymmetric attack vector.” As the technology of fake news becomes more advanced, and the media landscape more complex, it is vital to have machines that can combat this progression.
“We’re sitting in a world that’s more complex than we can understand, we’re being manipulated by technologies that are very primitive but are going to get much more advanced, that’s the bad picture,” said Gourley, “but on the other side we have machines that can teach us about what’s going on in the world, can show us things we haven’t seen but probably should see, and can start to do a lot of that ground work for us. As we look at the next decade coming forward, we’re going to see this battle between manipulation and understanding.”
It is clear which side of that battle Primer is on. Gourley noted that the new technology will help people understand better, know more, and safeguard themselves from the kind of manipulation that is already taking affect around the world. It’s new but absolutely vital territory for AI.













